How to Introduce Your Adopted Pet to Existing Pets
Supervised Learning Fundamentals
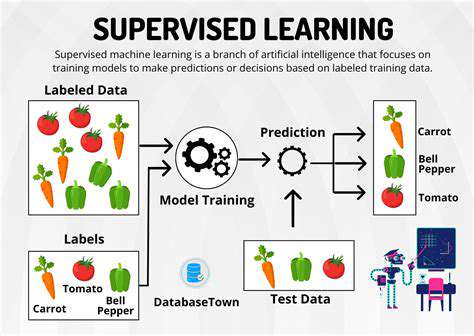
Supervised learning is a cornerstone of machine learning, where algorithms learn from labeled data. This labeled data provides input-output pairs, allowing the algorithm to identify patterns and relationships between variables. Crucially, this process of learning from labeled examples enables the model to generalize to new, unseen data, a key characteristic of successful predictive modeling. The goal is to develop a model capable of accurately predicting outcomes for future instances based on their input features.
Different supervised learning techniques exist, each tailored to specific tasks. Regression models, for example, predict continuous values, while classification models predict categorical outcomes. Understanding the nuances of each technique is essential for selecting the appropriate approach for a given problem. Choosing the right algorithm is a crucial step in the process of building a successful supervised learning model.
Data Preparation and Preprocessing
Before training any supervised learning model, careful data preparation and preprocessing are essential. This often involves handling missing values, transforming data to a suitable format, and addressing potential outliers. These steps are vital in ensuring the model's accuracy and preventing issues that could lead to inaccurate predictions.
Data cleaning and transformation techniques play a crucial role in ensuring the quality of the data used for model training. Data normalization, standardization, and encoding are common preprocessing steps that can significantly improve the model's performance. Understanding how to effectively clean and transform data is a critical skill for any data scientist or machine learning practitioner.
Feature engineering is another vital aspect of data preparation. This process involves creating new features from existing ones to improve the model's ability to learn complex patterns in the data. Feature engineering is a skill that can significantly impact the performance and accuracy of a supervised learning model.
Model Selection and Training
Selecting the appropriate model for a particular problem is a crucial step in the supervised learning process. Considering the nature of the data, the desired outcome, and the complexity of the task will help in choosing the right model. Different models have different strengths and weaknesses, and understanding these characteristics is vital for achieving optimal performance.
Once a model is chosen, the next step is training it on the prepared data. This involves feeding the data into the model and adjusting its parameters to minimize errors in its predictions. The training process usually involves iterations and optimization techniques to fine-tune the model's performance.
Choosing the right model and optimizing its training process are critical for creating a robust and accurate model. This process can be iterative and require various tuning techniques depending on the model and dataset.
Evaluation Metrics and Model Tuning
Evaluating the performance of a trained supervised learning model is paramount to assessing its effectiveness. Various metrics, such as accuracy, precision, recall, and F1-score, are used to quantify the model's predictive capabilities. Understanding how these metrics relate to specific problem contexts is key to interpreting the model's performance.
Model tuning is an iterative process that involves adjusting model parameters to optimize its performance. This often involves techniques such as hyperparameter tuning, which fine-tunes the model's internal settings to achieve better predictive accuracy.
Deployment and Monitoring
Once a supervised learning model performs well in the evaluation phase, it's ready for deployment. This involves integrating the model into a system that can receive new data and generate predictions. The deployment process needs to be carefully designed to ensure the model's reliability and scalability.
Continuous monitoring of the model's performance is crucial for maintaining its accuracy and reliability over time. Changes in the underlying data distribution can affect the model's predictions, so monitoring for these changes is essential to ensure the model remains effective. Maintaining the model's performance in a real-world setting requires careful monitoring and adaptation to new data and conditions.
Normal anxiety is a natural human response to stressful situations. It's a feeling of worry, nervousness, or unease, typically triggered by anticipated challenges or potential threats. This feeling, while uncomfortable, is often temporary and serves a purpose, prompting us to prepare and adapt. For example, feeling anxious before an important presentation helps us focus and rehearse, ultimately leading to a better outcome. Recognizing the difference between this healthy, manageable anxiety and a more severe form is crucial for effective self-care and seeking appropriate support when needed.
Read more about How to Introduce Your Adopted Pet to Existing Pets



![My Story of Rescuing a Bird [Story]](/static/images/33/2025-06/ATriumphantReturntoFreedom.jpg)



![Life with My [Specific Pet Type/Breed] [Pet Diary]](/static/images/33/2025-07/TheUnbreakableBond3AMyPersianCompanion.jpg)


![My Experience Rescuing a Farm Animal [Story]](/static/images/33/2025-07/BringingthePigletHome.jpg)
![My First Time Fostering a Kitten [Story]](/static/images/33/2025-08/LessonsLearnedandFuturePlans.jpg)
Hot Recommendations
- Review: [Specific Brand] Small Animal Cage
- Why Rescuing Pets Saves Lives
- Best Pet First Aid Kits [What to Include]
- How to Help Stray Animals in Your Community
- Guide to Adopting a Pet When You Have Kids
- Top Reptile Heat Lamps
- Heartwarming Rescue Stories That Will Inspire You
- Review: [Specific Brand] Bird Cage
- Best Aquarium Filters [2025 Review]
- Review: [Specific Brand] Smart Litter Box